





























Data classification is the foundation of cyber resilience. Organisations cannot protect what they do not understand. When information is not classified, security controls are applied blindly, exposing sensitive data while over protecting low value content. This article explains why data classification is the first step in cyber resilience, how information security classification works, and how organisations can implement it effectively.
What is data classification?
Data classification is the process of categorising information based on its sensitivity, value, and risk if compromised. Common classifications include public, internal, confidential, and highly sensitive.
The core problem it addresses is uniform security. When all data is treated the same, controls are either too weak for critical information or too heavy for everyday use. Both outcomes increase risk¹.
A data classification framework establishes a shared language for information risk. It allows organisations to align protection, access, and handling rules with actual data sensitivity rather than assumptions.
Why is data classification the first step in cyber resilience?
Cyber resilience depends on prioritisation. Organisations must know which information requires the strongest protection and which can tolerate more flexible controls.
Without classification, incident response becomes reactive. Teams cannot quickly assess impact because they do not know what data was affected. Recovery is slower and reporting is less reliable².
Data classification also underpins other security disciplines. Identity access management, encryption, retention, and monitoring all depend on understanding what data they are protecting.
How does information security classification work in practice?
Defining classification levels and criteria
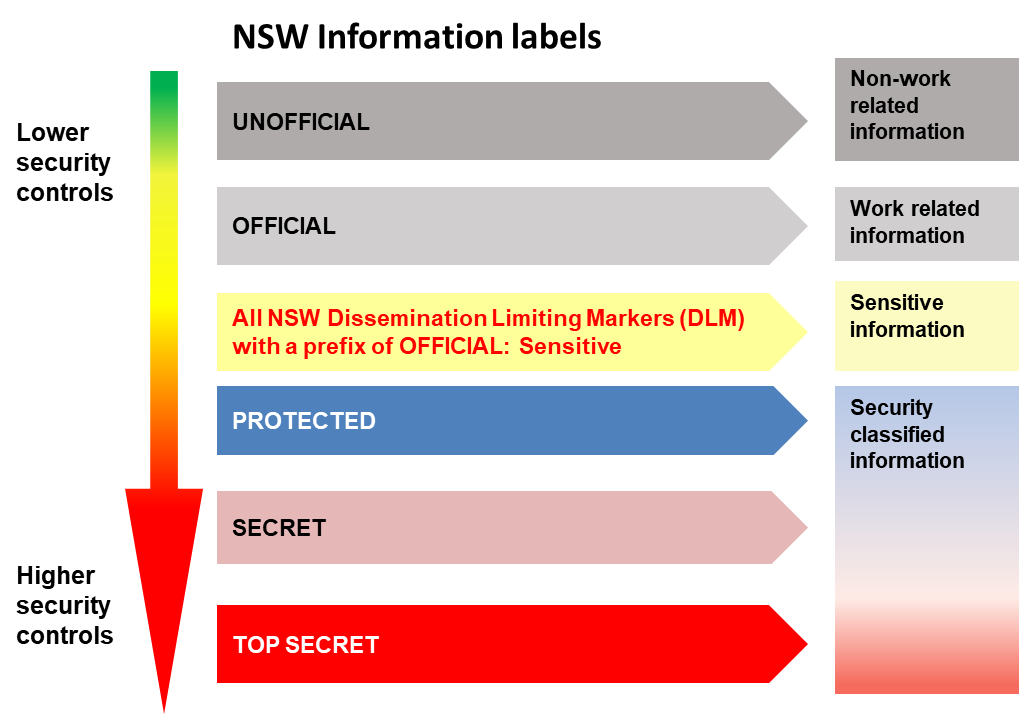
Effective information security classification starts with clear, limited levels. Each level must have defined criteria based on confidentiality, integrity, and availability.
For example, highly sensitive data may include personal information, security details, or commercially confidential material. Public data carries minimal risk if disclosed.
Classification criteria must be practical. Overly complex models reduce adoption and accuracy.
Applying controls based on classification
Once classified, information security controls are applied proportionally. Higher classifications require stronger access control, encryption, monitoring, and handling procedures.
Lower classifications allow greater sharing and reuse, improving productivity without increasing risk³.
This proportionality aligns with guidance and expectations set by the Australian Government and international security standards.
How does data classification support cyber resilience beyond security?
Data classification is not only a security tool. It supports operational resilience and recovery.
During incidents, classification allows rapid triage. Teams know which systems and datasets require immediate attention and regulatory notification.
Classification also supports business continuity. Critical information can be prioritised for backup, recovery testing, and redundancy, ensuring essential services remain available⁴.
How does data classification differ from data governance?
Data governance defines ownership, decision rights, and policies. Data classification operationalises those decisions at the information level.
Governance answers who decides and why. Classification answers how information is handled day to day.
Without governance, classification lacks authority. Without classification, governance remains theoretical. Both are required for effective cyber resilience.
Where do organisations struggle with data classification?

Over classification
Many organisations classify too much data as high risk. This slows work and encourages staff to bypass controls.
Classification should be evidence based. Not all data is equally sensitive.
Manual classification and inconsistency
Relying solely on manual classification is unsustainable at scale. Inconsistency undermines trust in the framework.
Information Management and Protection solutions support automation and policy driven classification while maintaining oversight.
What risks arise when data is not classified?
Unclassified data increases exposure. Sensitive information may be shared or stored without adequate protection.
It also increases response risk. During incidents, organisations cannot accurately assess impact, delaying containment and reporting⁵.
In regulated environments, failure to classify data undermines compliance with privacy, security, and records obligations.
How should organisations implement a data classification framework?
Implementation should begin with high value and high risk information rather than enterprise wide rollout.
Key steps include defining classification levels, mapping critical information assets, and embedding classification into systems and workflows.
Knowledge Quest supports this by applying classification rules to content and guidance, ensuring staff handle information correctly without memorising policies.
Customer Science Insights then links classified information to CX and operational outcomes, showing where security controls protect service delivery rather than obstruct it.
How should success be measured?
Success is measured by risk reduction and usability.
Indicators include reduced security incidents involving sensitive data, faster incident response, and improved staff confidence in handling information.
Over time, classification maturity should reduce both breach impact and productivity loss.
What are the next steps toward cyber resilience?
Organisations should start with a data classification maturity assessment. This identifies gaps between policy intent and operational reality.
CX Consulting and Professional Services can support design of classification frameworks aligned to business and regulatory context. Information Management and Protection solutions then embed classification into systems, processes, and training.
CommScore AI should be deployed only once data is correctly classified, ensuring analytics and automation do not expose sensitive information.
The goal is targeted protection that strengthens resilience without slowing delivery.
Evidentiary Layer
Research consistently shows that data classification improves cyber resilience by enabling proportional security controls. ISO standards emphasise classification as a prerequisite for information security management systems⁶. Government guidance similarly highlights classification as foundational to protecting critical and sensitive information⁷.
FAQ
What is data classification?
It is the categorisation of information based on sensitivity and risk.
Why is data classification critical for cyber resilience?
Because organisations cannot protect or prioritise response without knowing data value.
How many classification levels should be used?
As few as practical. Simplicity improves consistency and adoption.
Is data classification only a security activity?
No. It supports compliance, resilience, and operational efficiency.
What tools support data classification?
Information Management and Protection solutions, Knowledge Quest, and Customer Science Insights support governed classification.
Where should organisations start?
With high risk and high value information that underpins critical services.
Sources
-
ISO IEC 27001, Information Security Management Systems, 2022.
-
ISO IEC 27002, Information Security Controls, 2022.
-
ISO IEC 38505-1, Governance of Data, 2017.
-
Australian Cyber Security Centre, Essential Eight Maturity Model, 2023.
-
Australian National Audit Office, Cyber Security Risk Management, 2021.
-
ISO IEC 27005, Information Security Risk Management, 2018.
-
Australian Government, Protective Security Policy Framework, 2023.