





























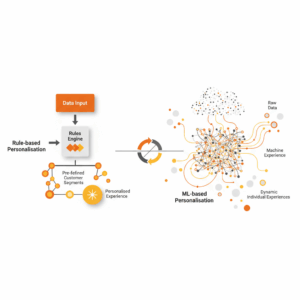
What is personalisation and why does the choice of approach matter?
Leaders set strategy when they define personalisation as the delivery of content, offers, or service treatments that adapt to the individual based on signals such as behaviour, context, and identity. Customers now expect relevance as standard and react when it is missing. Research shows that 71 percent of consumers expect companies to deliver personalised interactions, and 76 percent get frustrated when this does not happen.¹ Personalisation has become a core lever for growth, not a nice-to-have.² The implementation approach shapes cost, speed, risk, and the ceiling on performance. Rule-based personalisation uses explicit if–then logic and human-crafted segments. ML-based personalisation uses models that learn patterns and optimise decisions from data. Both can be effective. Each shines in specific conditions. The right choice depends on data readiness, governance constraints, experience complexity, and the pace of change in customer signals.¹
How do rule-based and ML-based approaches differ in practice?
Teams ship rule-based experiences by encoding business logic such as “If customer is a member and cart value is above a threshold, then show free shipping” or “If user comes from a campaign, then show a landing variant.” Rule systems are transparent and quick to audit. They create predictable outcomes and align well with regulated processes. ML-based approaches learn from historical and real-time data. They predict the best message, next action, or layout and they update as behaviour shifts. Netflix illustrates this with artwork selection that changes by member to increase engagement.³ Personalisation extends across images, trailers, and synopses to present the most compelling representation of a title.⁴ ML systems can also explore new options while serving the current best choice, which gives an edge in fast-moving contexts with many variants.⁵
When should leaders prefer rule-based personalisation?
Executives choose rules when clarity and control matter most. Rule-based personalisation fits environments with explicit policies, limited data, and narrow decision spaces. It excels at codifying eligibility, pricing constraints, and service entitlements. It lowers operational risk in journeys like complaints handling, vulnerability routing, and regulated disclosures. Rules also help when telemetry is sparse or delayed. They remain useful for housekeeping such as campaign targeting, geo or language selection, and identity-led recognisers like loyalty tiers. Rule logic is easier to test with simple A/B designs and easier to roll back.⁷ In early maturity stages, rules unlock quick wins while data pipelines and consent frameworks mature. Teams should still measure outcomes, retire stale rules, and prevent rule creep. A living catalogue and conflict detection protect against brittle logic and silent clashes between campaigns and service policies.⁷
Where does ML-based personalisation pay off?
Leaders adopt ML when complexity and scale exceed human rule-writing capacity. ML drives lift when there are many items, many contexts, and fast-changing preferences. It suits recommendations, next-best-action decisions, and creative optimisation where dozens of variants compete for attention. Netflix reports meaningful engagement gains from personalising artwork at the title level, which illustrates the value of granular choices at scale.³ ⁴ ML also improves with time as feedback loops enrich training data and as models adapt to seasonality, content drift, and new cohorts. Contextual bandits and related methods optimise choices while continuing to learn, which reduces opportunity cost compared with static testing.⁵ ⁶ When the option space explodes, ML is the only sustainable way to keep pace. Organisations that pair ML with rigorous experimentation acquire a durable advantage in speed to insight and in the upper bound of performance.⁷
How do contextual bandits make real-time choices?
Contextual bandits select an action that balances learning and earning for each user context. The system observes features such as device, time, and behaviour, then chooses a variant and observes the reward. It updates its policy to improve the next choice.⁵ Unlike traditional supervised learning, bandits optimise the objective directly in production with controlled exploration.⁶ This suits on-site modules like hero banners, navigation tiles, or call-centre prompts where feedback arrives quickly. The method reduces the need for long sequential A/B tests across many variants, since the policy shifts toward winners during the run.⁵ Teams must still set guardrails, log exposure, and monitor bias. Good implementations integrate with AutoML or experimentation platforms to track confidence, detect drift, and throttle exploration for sensitive cohorts.⁵ ⁶
What are the risks, privacy, and governance considerations?
Risk increases when decisions affect price, access, or outcomes that carry legal or similarly significant effects. Article 22 of the UK GDPR restricts solely automated decisions of this kind and sets conditions and safeguards.⁸ If a process falls outside Article 22, organisations must still follow GDPR principles including transparency, lawful basis, and fairness.⁹ These requirements apply to both rules and ML. ML adds model risk through opacity, drift, and feedback loops. Rule systems add operational risk through hidden dependencies and unmanaged overrides. Leaders should implement decision inventories, impact assessments, and model cards. Clear human-in-the-loop designs help when stakes are high. Data minimisation, purpose limitation, and consent capture protect legitimacy. Regular reviews of input features and outcomes protect against proxy bias and discriminatory effects.⁸ ⁹
How should leaders measure impact and build trust?
Teams earn trust by running online controlled experiments and maintaining strong data quality. A well-designed A/B test isolates causal impact and prevents overclaiming based on correlation.⁷ Leaders should instrument exposure, define primary metrics, and pre-register hypotheses for material launches. Robust guardrails avoid harm by watching for negative movements in latency, contact rate, or complaint volume. Analytical discipline matters as much as model selection.⁷ In practice, rule and ML variants should compete within the same framework to quantify incremental value. Observability should cover data freshness, feature drift, and outcome stability. Clear owner dashboards support rapid rollback. Analysts should publish experiment summaries with effect sizes, confidence intervals, and operational learnings.⁷ These habits move personalisation from anecdotes to evidence and keep the portfolio focused on business outcomes.
Which approach should you choose today?
Executives should decide with a short diagnostic. Choose rules if your decision space is small, policy driven, and audit heavy. Choose ML if your option space is large, signals are rich, and speed to adapt matters. Use rules to encode constraints and eligibility, then let ML optimise within the safe region. Treat personalisation as a decision system rather than a widget. Map the decision, the policy guardrails, the optimisation layer, and the learning loop. In content surfacing and creative choice, ML with contextual bandits will usually outperform static rules because it adapts during the run and scales across variants.⁵ ⁶ In sensitive decisions, rules with human review may remain mandatory to meet Article 22 constraints.⁸ This layered architecture keeps both approaches in play and aligns technical choices with risk appetite and growth ambition.
How do you migrate from rules to ML without breaking journeys?
Leaders stage the migration in four moves. First, stabilise identity and consent foundations to ensure lawful, high-quality signals. Second, clean the rule estate by consolidating duplicates and removing dead logic. Third, introduce ML in low-risk placements such as image or content ranking. Netflix’s evolution in artwork and asset selection shows how granular ML choices grow engagement without touching price or eligibility.³ ⁴ Fourth, extend ML to next-best-action and channel orchestration once experimentation and observability mature. Throughout the journey, wrap ML with business rules that enforce policy and fairness. Use A/B tests to quantify value and pause escalations when harm is detected.⁷ Use contextual bandits where feedback is rapid and where the experience offers many comparable options.⁵ ⁶ This flow reduces risk while unlocking compounding gains.
What does good look like in production?
High-performing teams run a two-tier decisioning stack. A policy layer encodes eligibility, regulatory constraints, and safety filters. A learning layer uses ML to optimise content, sequence, and timing within those constraints. The stack logs every decision with inputs, versioned models or rule sets, and outcomes for audit. The analytics muscle runs trustworthy experiments and publishes learnings.⁷ Marketing, product, and service teams use shared success metrics such as conversion, engagement, contact rate, and NPS. Design teams feed creative variants into the system with clear metadata to enable learning. Netflix demonstrates this pattern by applying personalisation not only to recommendations but also to the presentation of titles through artwork and synopses, which increases the probability of selection.³ ⁴ The operating model treats personalisation as a product, not a project, with roadmaps and accountability.
What is the simple playbook for your next quarter?
Teams can act now with a focused plan. Choose two high-traffic surfaces for ML testing and two policy-heavy flows for rule hardening. Instrument exposure and define primary metrics. Stand up a contextual bandit or multi-armed bandit for a creative module with many variants.⁵ ⁶ Run trustworthy A/B tests to quantify gains and document learnings.⁷ Update your Article 22 assessments and publish a short transparency note for customers.⁸ ⁹ Close the quarter by retiring underperforming rules and promoting validated models to a controlled rollout. This rhythm builds confidence, earns value, and sets a sustainable path from rules to ML.
FAQ
What is the difference between rule-based and ML-based personalisation?
Rule-based personalisation uses explicit if–then logic crafted by humans to deliver predefined treatments. ML-based personalisation learns patterns from data to predict or optimise the best treatment for each customer.³ ⁵
When should a contact centre prefer rule-based personalisation?
A contact centre should prefer rules when decisions encode eligibility, vulnerability handling, or regulated disclosures that must be transparent and auditable. Rules fit small decision spaces and policy-heavy flows.⁷ ⁸
Why do contextual bandits help with creative and offer optimisation?
Contextual bandits balance learning and earning by exploring variants while serving likely winners for each context. This reduces the time and traffic wasted on poor variants compared with static tests.⁵ ⁶
Which governance rules apply to automated decisions under the UK GDPR?
Article 22 restricts solely automated decisions, including profiling, that produce legal or similarly significant effects. Organisations must provide safeguards and respect transparency, fairness, and lawful basis requirements.⁸ ⁹
How should leaders measure personalisation impact with confidence?
Leaders should run online controlled experiments with clear hypotheses, primary metrics, and guardrails. Proper A/B testing isolates causal impact and prevents overclaiming from correlations.⁷
Who demonstrates effective ML personalisation at scale?
Netflix showcases effective ML personalisation by adapting artwork, trailers, and synopses for each member to increase engagement and selection.³ ⁴
What first steps should CX teams take to migrate from rules to ML?
CX teams should stabilise identity and consent data, prune overlapping rules, pilot ML on low-risk placements, and wrap models in policy guardrails with trustworthy experimentation to validate gains.⁵ ⁷ ⁹
Sources
“The value of getting personalization right—or wrong—is multiplying,” McKinsey & Company, 2021, Growth, Marketing & Sales. https://www.mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/the-value-of-getting-personalization-right-or-wrong-is-multiplying
“Unlocking the next frontier of personalized marketing,” McKinsey & Company, 2025, Growth, Marketing & Sales. https://www.mckinsey.com/capabilities/growth-marketing-and-sales/our-insights/unlocking-the-next-frontier-of-personalized-marketing
Gomez-Uribe, C., et al., “Artwork Personalization at Netflix,” Netflix TechBlog, 2017. https://netflixtechblog.com/artwork-personalization-at-netflix-c589f074ad76
Carterette, B., et al., “Discovering Creative Insights in Promotional Artwork,” Netflix TechBlog, 2023. https://netflixtechblog.com/discovering-creative-insights-in-promotional-artwork-295e4d788db5
Google Cloud, “How to build better contextual bandits machine learning models,” 2019, Google Cloud Blog. https://cloud.google.com/blog/products/ai-machine-learning/how-to-build-better-contextual-bandits-machine-learning-models
Ban, Y., Qi, Y., He, J., “Neural Contextual Bandits for Personalized Recommendation,” 2023, arXiv. https://arxiv.org/abs/2312.14037
Kohavi, R., Tang, D., Xu, Y., “Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing,” 2020, Cambridge University Press. https://www.cambridge.org/core/books/trustworthy-online-controlled-experiments/D97B26382EB0EB2DC2019A7A7B518F59
UK Information Commissioner’s Office, “What does the UK GDPR say about automated decision-making and profiling?,” 2025, Guidance. https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/individual-rights/automated-decision-making-and-profiling/what-does-the-uk-gdpr-say-about-automated-decision-making-and-profiling/
UK Information Commissioner’s Office, “Rights related to automated decision making including profiling,” 2025, Guidance. https://ico.org.uk/for-organisations/uk-gdpr-guidance-and-resources/individual-rights/individual-rights/rights-related-to-automated-decision-making-including-profiling/