





























What is data lineage and why does it matter to CX leaders?
Data lineage shows how data moves from source to consumption and how people and systems transform it along the way. Leaders use lineage to answer simple questions with complex implications, like who touched this field and what breaks if this table changes. Clear lineage reduces decision risk, speeds incident response, and strengthens trust in AI, analytics, and reporting. Open frameworks now make lineage collection practical across modern stacks, rather than a brittle, diagram-only exercise.¹ Lineage also supports compliance duties that require accuracy and transparency in regulated data flows.² ³
How should executives frame lineage goals before buying tools?
Executives set intent first. State the customer and business outcomes that lineage must enable, then shape scope. Target three outcomes. First, improve reliability of customer analytics with upstream impact analysis for every change. Second, shorten time to resolve data incidents by tracing breakage to the exact job, dataset, or field. Third, meet regulatory expectations for accuracy, auditability, and traceability across personal and risk data domains.² ³ ⁴ Scope then defines minimum viable coverage by system, by pipeline, and by column for high materiality entities like churn models, case management reports, and customer identity.
What architecture captures lineage without redesigning your stack?
Teams implement a layered design that emits, stores, and visualizes lineage. Capture lineage events from orchestrators and engines using the OpenLineage specification, which standardizes jobs, runs, inputs, and outputs so tools can interoperate.¹ ⁵ Instrument Airflow with the OpenLineage provider to emit run events for tasks and DAGs with no rebuild of pipelines.⁶ Store and enrich lineage in a metadata platform such as Apache Atlas, DataHub, or OpenMetadata that supports table and often column level relationships, plus programmatic APIs for read and write.⁷ ⁸ ⁹ Choose a single system of record for lineage and synchronize from others to avoid conflicting graphs.
What is the step by step path from zero to credible lineage?
Leaders start small and build momentum in nine moves.
Step 1. Define critical data products. Select the five to ten analytics products that drive revenue, cost, or risk decisions. Name owners, SLAs, and downstream consumers. Write success criteria in plain language.
Step 2. Adopt a common lineage spec. Choose OpenLineage for event vocabulary so ingestion from Airflow, Spark, dbt, and notebooks stays consistent across teams. Emit run events with consistent namespace and job naming.¹ ⁵ ⁶
Step 3. Stand up a metadata store. Deploy Atlas, DataHub, or OpenMetadata to persist assets, schemas, policies, and lineage edges. Validate that your choice supports search, impact analysis, and API access.⁷ ⁸ ⁹
Step 4. Enable automatic capture. Turn on orchestrator, warehouse, and BI integrations to harvest table level lineage. Use query log parsing or built-in connectors to infer edges when native hooks are missing.⁹ ¹⁰
Step 5. Add column level lineage for priority paths. Extend capture to fields that drive pricing, targeting, or risk models to improve root cause analysis. Many platforms now support column level extraction for major warehouses and BI tools.⁸ ¹¹
Step 6. Link lineage to data quality checks. Attach validations from tools like Great Expectations or Soda to datasets and jobs. Publish test results and run IDs into the same metadata system so broken edges and failed checks are visible on the graph.¹² ¹³ ¹⁴
Step 7. Operationalize impact analysis. Wire lineage queries into change control. Require a downstream impact report before schema changes or deprecations. Expose an at a glance view inside ticketing and release workflows.
Step 8. Close the loop with ownership. Assign accountable owners for each dataset and job. Route alerts to owners when downstream tests fail or when upstream contracts change.
Step 9. Measure and improve. Track coverage, freshness of edges, time to detect, and time to resolve incidents. Expand scope only after reliability and adoption targets are met.
How do Atlas, DataHub, and OpenMetadata compare for lineage?
Organizations want open, API first platforms with active communities. Apache Atlas offers robust governance, classification, and lineage, with strong enterprise adoption in Hadoop and hybrid estates.⁷ ¹⁵ DataHub provides programmatic lineage with table and column support, plus flexible filters and OpenLineage integration.⁸ ¹⁶ OpenMetadata supplies automated lineage ingestion, query log workflows, and end to end visualization across warehouses and BI tools.⁹ ¹⁰ Selection depends on your ecosystem, security model, and developer preferences. All three meet the baseline needs for storing and querying lineage graphs and exposing impact analysis to developers and analysts.
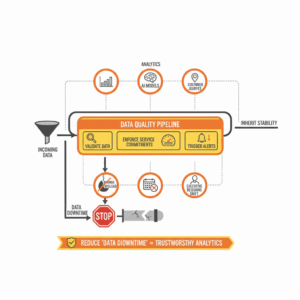
Where do quality, observability, and lineage meet?
Data quality asserts what good looks like. Data observability monitors freshness, volume, schema, and errors to detect anomalies. Lineage explains relationships so teams can triage impact and find root causes faster. Great Expectations turns expectations into testable checks and publishes human readable documentation that teams can share.¹² ¹⁷ Soda brings a declarative approach and contracts that connect producers and consumers.¹³ Observability platforms such as Monte Carlo overlay field and table lineage with incident workflows to cut mean time to repair.¹⁸ ¹¹ ¹⁹ Combining these units creates a control surface that prevents silent failures and protects customer trust.
What regulations and controls shape lineage requirements?
Customer and risk data carry explicit legal and supervisory expectations. The GDPR sets principles for data accuracy and transparency, which require organizations to ensure personal data is accurate and kept up to date, and to rectify inaccuracies without delay.² ²⁰ Banking supervisors require effective risk data aggregation and reporting, known as BCBS 239, which emphasizes strong data architecture, traceable aggregation, and accurate reporting to senior management.³ ²¹ Security frameworks like NIST SP 800 53 require auditable records that capture what happened, when it happened, and who performed the action, which aligns with lineage and provenance controls across pipelines.⁴ ²²
How do you measure success for lineage in production?
Teams measure four groups of indicators. Coverage measures how much of your critical data estate has lineage, at table and column level, and the proportion of edges verified by integration versus inference. Freshness measures the lag between pipeline execution and lineage availability, which must be near real time for reliable change control. Efficiency measures time to detect and time to resolve data incidents before downstream customers feel impact. Adoption measures how often engineers, analysts, and product teams query the graph during development, releases, and support. Observability vendors report that automated lineage reduces time to root cause by guiding responders directly to the failing transformation.¹⁹
What risks and anti patterns should leaders avoid?
Leaders avoid three traps. First, drawing static diagrams that quickly drift from the truth. Emit events and regenerate views from source systems so the graph stays living.¹ ⁶ Second, spreading lineage across multiple truth stores without synchronization. Choose a single lineage authority and federate views into catalogs. Third, treating lineage as a compliance checklist. Tie the graph to quality checks, incident runbooks, and change approvals so teams feel the benefit in daily work. When lineage sits in the path of change and recovery, adoption follows.
What are the next steps to get value within 90 days?
Teams can deliver value quickly. Start with Airflow or your scheduler and enable OpenLineage emission for a small portfolio of customer facing analytics.⁶ Stand up a metadata platform and ingest from the orchestrator, warehouse logs, and one BI tool.⁷ ⁸ ⁹ Attach two or three critical Great Expectations suites to the most important datasets and publish the results into the same store.¹² ¹⁷ Run weekly impact drills where developers use the graph to plan a change and responders use it to resolve a seeded incident. Report coverage, freshness, and incident metrics to the steering group. Expand only after the team demonstrates faster, safer changes with fewer customer impacts.
FAQ
How does OpenLineage standardize lineage events across tools?
OpenLineage defines a common specification and schema for jobs, runs, datasets, and their relationships so different systems can emit compatible lineage events and share a unified graph.¹ ⁵
What is the fastest way to collect lineage from Apache Airflow?
Install and configure the OpenLineage Airflow provider so tasks emit run events during execution. This captures job level inputs and outputs with minimal code changes.⁶
Which metadata platforms support table and column level lineage today?
Apache Atlas, DataHub, and OpenMetadata each provide lineage storage, APIs, and visualization. DataHub and OpenMetadata document column level lineage for major warehouses and BI tools.⁷ ⁸ ⁹ ¹¹
Why does GDPR change how we manage lineage for customer data?
GDPR requires personal data to be accurate and up to date, with prompt rectification of inaccuracies. Lineage supports accuracy by tracing sources and transformations that may introduce errors and by enabling quick correction.²
Which supervisory standard drives lineage for risk data in banks?
BCBS 239 sets principles for effective risk data aggregation and reporting, which require strong data architecture, traceable aggregation, and reliable reporting to management.³
How do data quality tools plug into lineage to speed recovery?
Great Expectations and Soda attach validations to datasets and jobs. When a check fails, responders use lineage to trace upstream dependencies and find the failing step faster.¹² ¹³ ¹⁷
Which metrics prove lineage is working in production?
Track coverage at table and column level, freshness of lineage events, time to detect and time to resolve incidents, and usage of lineage queries in change and support workflows.¹⁹
Sources
-
OpenLineage documentation. OpenLineage Project. 2025. Project docs. https://openlineage.io/docs/
-
GDPR Article 5: Principles relating to processing of personal data. European Union. 2016. Legislation text. https://gdpr-info.eu/art-5-gdpr/
-
Principles for effective risk data aggregation and risk reporting. Basel Committee on Banking Supervision. 2013. BIS publication. https://www.bis.org/publ/bcbs239.pdf
-
Security and Privacy Controls for Information Systems and Organizations, Revision 5. Joint Task Force, NIST. 2020. Special Publication 800-53r5. https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-53r5.pdf
-
OpenLineage Object Model and Schemas. OpenLineage Project. 2025. Project docs. https://openlineage.io/docs/spec/object-model/ and https://openlineage.io/docs/spec/schemas/
-
OpenLineage Airflow integration guide. Apache Airflow. 2025. Provider docs. https://airflow.apache.org/docs/apache-airflow-providers-openlineage/stable/guides/structure.html
-
Apache Atlas website and lineage overview. Apache Software Foundation and Cloudera Docs. 2023–2025. Project and product docs. https://atlas.apache.org/ and https://docs.cloudera.com/runtime/7.3.1/atlas-exploring-using-lineage/topics/atlas-lineage-overview.html
-
DataHub lineage guides and SDK. DataHub Project. 2025. Documentation. https://docs.datahub.com/docs/features/feature-guides/lineage and https://docs.datahub.com/docs/api/tutorials/lineage
-
OpenMetadata lineage how-to and workflows. OpenMetadata Project. 2025. Documentation. https://docs.open-metadata.org/latest/how-to-guides/data-lineage and https://docs.open-metadata.org/latest/connectors/ingestion/workflows/lineage
-
OpenMetadata lineage via query logs. OpenMetadata Project. 2025. Documentation. https://docs.open-metadata.org/latest/connectors/ingestion/workflows/lineage
-
Field lineage documentation. Monte Carlo. 2025. Product docs. https://docs.getmontecarlo.com/docs/field-lineage
-
Great Expectations official site and docs. GX Maintainers. 2025. Project site and documentation. https://greatexpectations.io/ and https://docs.greatexpectations.io/docs/home/
-
Soda data quality overview and lineage primer. Soda. 2025. Product site and resource. https://www.soda.io/ and https://www.soda.io/resources/data-lineage-101
-
Data lineage and impact analysis product page. Monte Carlo. 2025. Product site. https://www.montecarlodata.com/platform/data-lineage-impact/
-
What is Apache Atlas. Atlan. 2025. Overview article. https://atlan.com/what-is-apache-atlas/
-
DataHub OpenLineage integration configuration. DataHub Project. 2025. Documentation. https://docs.datahub.com/docs/lineage/openlineage
-
Data Docs concept. Great Expectations Documentation. 2025. Reference. https://docs.greatexpectations.io/docs/0.18/reference/learn/terms/data_docs/
-
The Ultimate Guide to Data Lineage. Monte Carlo. 2025. Article. https://www.montecarlodata.com/blog-data-lineage/
-
What is Data Observability. Monte Carlo. 2025. Article. https://www.montecarlodata.com/blog-what-is-data-observability/