





























Summary
Business intelligence fails when poor data enters the system. Garbage in, garbage out remains the defining risk in BI. Data engineering creates the structures, controls, and quality foundations that make analytics reliable. Without it, dashboards mislead, decisions degrade, and trust collapses. Strong data engineering turns BI from opinion support into decision infrastructure.
What does “garbage in, garbage out” mean in BI?
Garbage in, garbage out describes the direct relationship between data quality and insight quality. If source data is incomplete, inconsistent, or poorly defined, BI outputs inherit those flaws.
In modern BI environments, data flows from multiple systems, channels, and vendors. Errors compound quickly. Executives may see precise numbers that are fundamentally wrong. Research consistently shows that data quality issues are a leading cause of BI failure and low adoption¹. Data engineering exists to prevent this outcome.
Why does poor data quality undermine BI trust?
Trust is fragile in analytics. Once stakeholders identify errors or inconsistencies, confidence erodes rapidly. Users revert to spreadsheets or intuition. BI becomes decorative rather than authoritative.
According to Gartner, organisations lose significant value from analytics investments due to unresolved data quality and integration issues². Poor quality also increases reconciliation effort, slowing decision cycles and increasing cost.
What is the role of data engineering in BI?
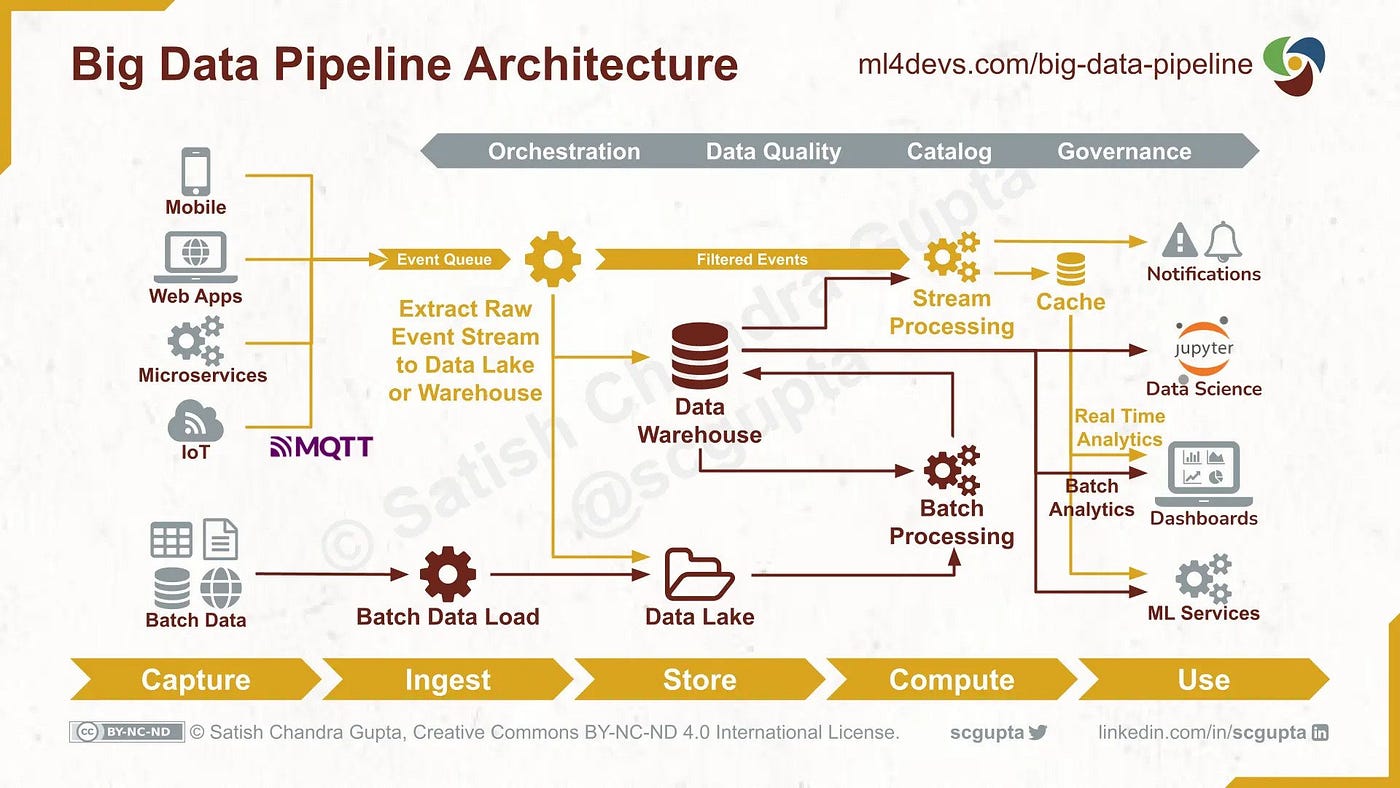
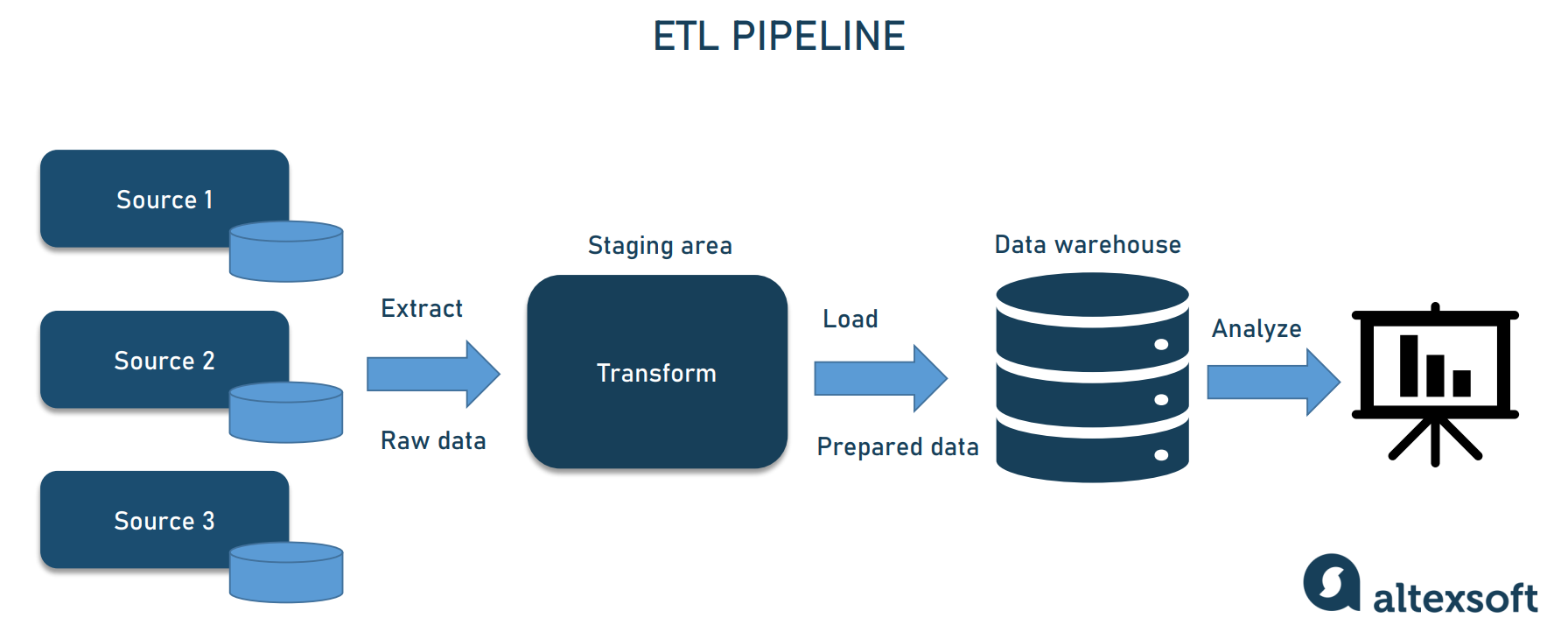
Data engineering designs and maintains the pipelines that ingest, transform, and deliver data for analytics. This includes integration, modelling, validation, and performance optimisation.
Effective data engineering enforces consistency across time, systems, and metrics. It ensures that definitions are stable, transformations are auditable, and outputs are fit for decision-making. BI tools visualise data. Data engineering determines whether that data deserves to be trusted.
How do data pipelines affect insight accuracy?
Pipelines translate operational data into analytical structures. Design choices determine how events are timestamped, how identities are resolved, and how exceptions are handled.
Weak pipelines introduce duplication, latency, and silent failure. Strong pipelines include validation checks, error handling, and lineage tracking. Studies show that automated data quality controls significantly reduce reporting defects and rework³. Accuracy is engineered, not assumed.
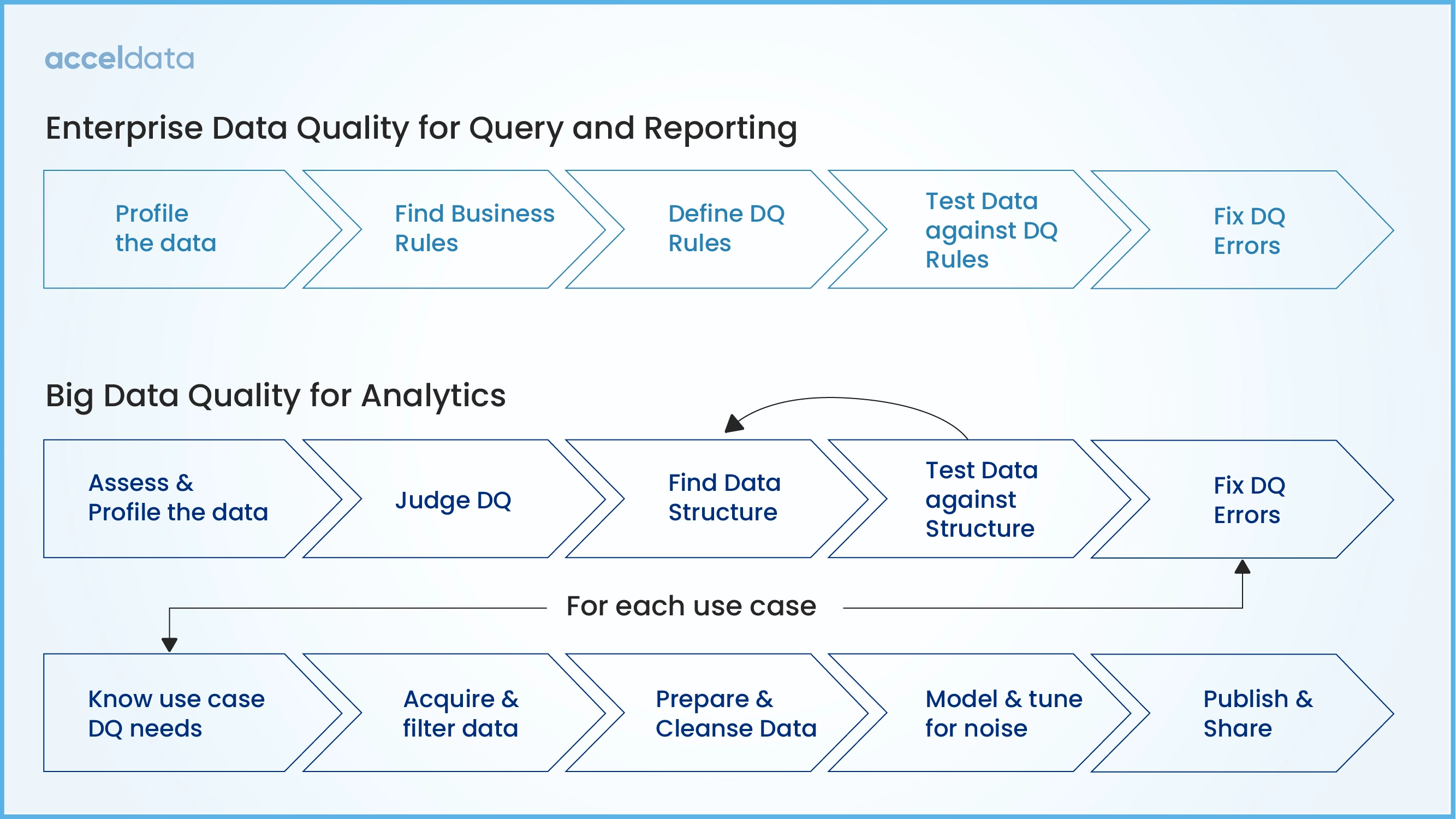
What standards define good data quality?
Data quality includes accuracy, completeness, consistency, timeliness, and validity. These dimensions must be defined and measured.
Standards such as ISO 8000 and ISO 25012 formalise data quality characteristics and governance responsibilities⁴. Aligning BI engineering to recognised standards reduces ambiguity and improves cross-team alignment.
How does data engineering differ from analytics and reporting?
Analytics focuses on analysis and interpretation. Reporting focuses on communication. Data engineering focuses on foundation.
Without engineering discipline, analytics teams spend most of their time fixing data rather than generating insight. Mature organisations separate these roles while ensuring close collaboration. This separation improves scalability and reduces dependency risk.
Where does data quality create the most BI value?
High-value areas include financial reporting, customer metrics, regulatory reporting, and executive dashboards. Errors in these domains have outsized impact.
Customer Science Insights accelerates value by providing governed data models and quality controls tailored to CX and operational analytics. This reduces engineering effort while improving consistency across BI outputs.
What risks arise from neglecting data engineering?
Neglect increases operational risk, compliance exposure, and reputational damage. In regulated sectors, inaccurate reporting can trigger enforcement action.
There is also cultural risk. Teams lose confidence in data. Decision-making fragments. Investment shifts away from analytics despite growing need. These outcomes are well documented in failed BI transformations⁵.
How should data quality be measured and monitored?
Data quality must be monitored continuously. Key indicators include:
-
Error rates and reconciliation effort
-
Data freshness and latency
-
Metric consistency across reports
-
Volume of manual overrides
Leading organisations treat data quality as an operational metric, not a one-off project. Continuous monitoring sustains trust and performance.
What are the next steps for leaders?
Leaders should assess data engineering maturity alongside BI tooling. This includes pipeline design, ownership, standards alignment, and quality monitoring.
Customer Science Business Intelligence and Information Management and Protection services support this work by designing robust data architectures, quality frameworks, and governance models aligned to enterprise risk and CX outcomes.
Evidentiary Layer
Customer Science product and service capabilities referenced in this article are based on official Customer Science documentation and solution descriptions.
FAQ
What is data engineering in BI?
Data engineering builds and maintains the pipelines and models that deliver trusted data for analytics and reporting.
Why is data quality so hard to maintain?
Because data comes from many systems with different definitions, incentives, and controls.
Can BI tools fix poor data quality?
No. BI tools expose data. They do not correct foundational quality issues.
Which Customer Science products support data quality?
Customer Science Insights provides governed analytics models with embedded quality controls.
How quickly can data quality improvements show value?
Improvements in trust and decision speed are often visible within weeks when quality issues are prioritised.
Is data engineering only relevant for large organisations?
No. Any organisation using BI at scale benefits from disciplined data engineering.
Sources
-
Redman T. Data Driven. Harvard Business Review Press. 2016.
-
Gartner. How poor data quality undermines analytics. 2021.
-
Batini C, Scannapieco M. Data Quality. Springer.
-
ISO 8000 Data quality standards.
-
Harvard Business Review. The dirty secret of big data. 2018.